正式严谨风
在进行千川建模型的操作过程中,究竟应该如何对各项参数及设置进行科学合理的安排呢?例如在数据准备阶段,需要选取哪些类型、规模的数据作为基础输入才能确保模型的准确性和泛化能力?在模型架构设计方面,是选择多层神经网络结构还是其他特定结构更为合适,以及各层神经元数量该如何确定?对于训练过程中的学习率、迭代次数等关键超参数,有没有通用的设置原则或者需要根据具体业务场景进行调整的方法呢?
通俗易懂风
我想了解一下,用千川建模型的时候,到底要怎么设置呀?比如说,一开始要准备哪些数据来让模型学习呢?这些数据有没有什么特别的要求?还有那个模型的结构,是不是就像搭积木一样,有不同的方式来组合?那到底哪种组合方式比较好呢?在训练模型的时候,像学习的速度、训练的次数这些,有没有一些简单的规则可以遵循,还是要根据具体情况来调整呢?
技术探究风
关于千川建模型的设置问题,我有一些深入的疑问,从数据预处理的角度来看,如何对原始数据进行清洗、归一化等操作,以消除噪声和量纲差异对模型的影响?在特征工程环节,怎样选择合适的特征提取方法,是将高维数据降维处理还是采用其他策略?在模型选型上,除了常见的深度学习算法,是否还有其他更适合千川场景的模型可供选择?如果选择了某种特定的模型,其初始化参数该如何设定,以避免陷入局部最优解?在模型训练过程中,如何监控和评估模型的性能指标,从而及时调整超参数以优化模型效果呢?

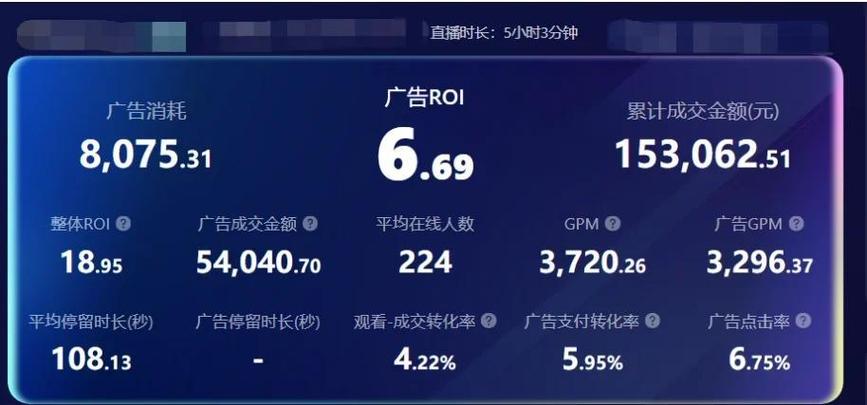
 文心AI解答
文心AI解答
取消评论你是访客,请填写下个人信息吧