
使用易解析PC客户端
1、准备工作:在电脑上下载并安装易解析PC客户端,同时准备好一个小红书账号。
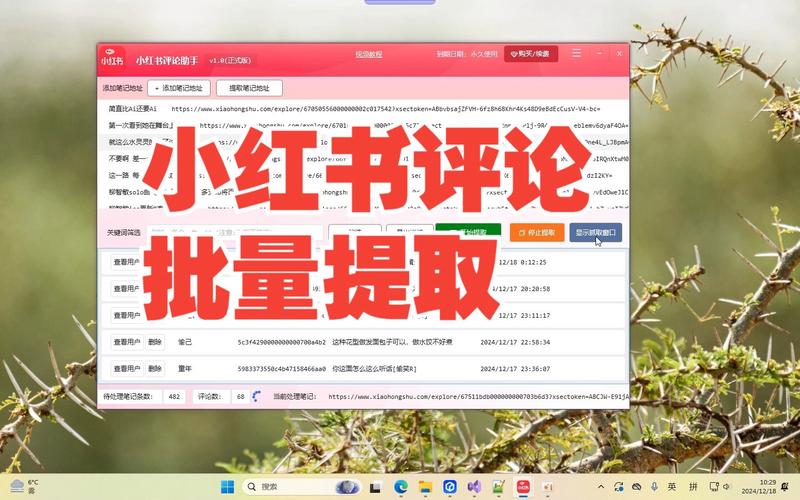
(图片来源网络,侵删)
2、操作步骤:打开易解析PC客户端,登录小红书账号,进入小红书主页,选择想要提取评论的帖子,点击“提取评论”按钮,软件将开始提取该帖子的所有评论,提取完成后,可将评论导出到电子表格中,表格中包含笔记名称、创作者、文章点赞数、收藏数、评论总数、各个评论的详情、评论者昵称、评论的点赞数以及评论的回复数等字段。
使用Python爬虫
1、准备工作:确保Python环境中已安装requests、beautifulsoup4、pandas等库,如果是爬取关键词相关笔记的评论,还需准备相应的关键词。
2、代码示例:以下是一个基本的Python爬虫代码框架,用于根据关键词爬取小红书笔记的评论:
import requests
from bs4 import BeautifulSoup
配置请求头和cookies
headers = {
'user-agent': '你的User-Agent',
'x-s': '加密串',
}
cookies = {
# 根据实际情况填写cookie内容
}
定义爬取函数
def fetch_comments(note_id):
url = f'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={note_id}'
response = requests.get(url, headers=headers, cookies=cookies)
data = response.json()
comments = data['data']['comments']
return comments
示例使用
comments = fetch_comments('示例笔记ID')
print(comments)需要注意的是,此代码仅为示例,实际使用时可能需要根据具体情况进行调整和完善,如处理分页、添加错误处理逻辑等。
使用小红书开放平台API
1、准备工作:注册开发者账号并申请相应的API权限,获取access_token。
2、代码示例:以下是使用API获取用户笔记评论数据的示例代码:
api_url = 'https://api.xiaohongshu.com/v2/notes/{note_id}/comments'
note_id = 'your_note_id'
access_token = 'your_access_token'
page = 1
limit = 10
构建完整的URL
url = api_url.format(note_id=note_id)
请求参数
params = {
'access_token': access_token,
'page': page,
'limit': limit
}
发送GET请求
response = requests.get(url, params=params)
检查响应状态
if response.status_code == 200:
data = response.json()
print(f"Status: {data['status']}")
print(f"Message: {data['message']}")
print(f"Code: {data['code']}")
comments = data['data']['comments']
for comment in comments:
print(f"Comment ID: {comment['comment_id']}")
print(f"User ID: {comment['user_id']}")
print(f"Content: {comment['content']}")
print(f"Like Count: {comment['like_count']}")
print(f"Created At: {comment['created_at']}")
print(f"Reply To: {comment['reply_to']}
")
pagination = data['data']['pagination']
print(f"Current Page: {pagination['current_page']}")
print(f"Total Pages: {pagination['total_pages']}")
print(f"Per Page: {pagination['per_page']}")
print(f"Total Count: {pagination['total_count']}")
else:
print(f"Error: {response.status_code}, {response.text}")同样,此代码仅为示例,实际应用中需要根据具体需求进行修改和扩展。
无论选择哪种方法提取小红书评论,都要注意遵守小红书的使用条款和相关法律法规,不要进行非法爬取和滥用数据。
- 上一篇:小红书如何隐藏字幕图片
- 下一篇:巨量引擎如何绑定千川?
相关推荐
- 02-01 如何经营小红书赚钱渠道
- 02-01 小红书如何设计头像框
- 02-01 小红书如何申请商品店铺
- 02-01 小红书如何变视频封面
- 02-01 如何关闭小红书续费会员
- 02-01 小红书如何刷关注内容
- 02-01 如何锁定小红书的收藏
- 02-01 如何评价小红书的评论
- 02-01 小红书如何设置封面图标
- 02-01 如何查看小红书销量榜
暂无评论
- 本月热门
- 最新答案
-
-

在自媒体行业中,教育领域的广告单价最高,这主要是因为教育内容具有较高的专业性和用户粘性,且教育类产品和服务往往具有较高价值,因此广告主愿意支付更高的费用。
宁静致远 回答于02-01
-

自媒体影视领域文章写作需聚焦热点话题,结合剧情解析、演员表现、幕后制作等多角度,运用故事叙述、观点评论等手法,创作思路在于深入挖掘内容价值,引发读者共鸣。
梦回吹角连营 回答于02-01
-

抖音小店报白通常需15-30个工作日,流程包括提交资料、审核、审批、开通。
文质彬彬 回答于02-01
-

开通今日头条原创功能需满足账号活跃、内容质量高、无违规记录等条件,具体申请流程和提交地点请参考图示。
浅夏微凉 回答于02-01
-

抖音视频上传模糊可以通过调整拍摄清晰度、使用清晰度修复工具等方法修复;避免上传模糊需注意拍摄光线、清晰度设置,并选择高质量视频格式。
英才大略 回答于02-01
-





取消评论你是访客,请填写下个人信息吧